Advanced Physical Modelling in Memory
In the previous tutorial, we simply modelled the chemistry of a static cloud for 1 Myr. This is unlikely to meet everybody's modelling needs and UCLCHEM is capable of modelling much more complex environments such as hot cores and shocks. In this tutorial, we model both a hot core and a shock to explore how these models work and to demonstrate the workflow that the UCLCHEM team normally follow.
import uclchem
import matplotlib.pyplot as plt
import pandas as pd
The Hot Core
Initial Conditions (Stage 1)
UCLCHEM typically starts with the gas in atomic/ionic form with no molecules. However, this clearly is not appropriate when modelling an object such as a hot core. In these objects, the gas is already evolved and there should be molecules in the gas phase as well as ice mantles on the dust. To allow for this, one must provide some initial abundances to the model. There are many ways to do this but we typically chose to run a preliminary model to produce our abundances. In many UCLCHEM papers, we refer to the preliminary model as stage 1 and the science model as stage 2. Stage 1 simply models a collapsing cloud and stage 2 models the object in question.
To do this, we will use uclchem.model.cloud() to run a model where a cloud of gas collapses from a density of to our hot core density of , keeping all other parameters constant. During this collapse, chemistry will occur and we can assume the final abundances of this model will be reasonable starting abundances for the hot core.
# set a parameter dictionary for cloud collapse model
param_dict = \{
"endAtFinalDensity": False, # stop at finalTime
"freefall": True, # increase density in freefall
"initialDens": 1e2, # starting density
"finalDens": 1e6, # final density
"initialTemp": 10.0, # temperature of gas
"finalTime": 6.0e6, # final time
"rout": 0.1, # radius of cloud in pc
"baseAv": 1.0, # visual extinction at cloud edge.
\}
df_stage1_physics, df_stage1_chemistry, df_stage1_rates, final_abundances, result = (
uclchem.model.cloud(
param_dict=param_dict,
return_dataframe=True,
)
)
df_stage1_chemistry
| H | H+ | H2 | H2+ | H3+ | HE | HE+ | HEH+ | C | C+ | ... | @OCS | @C4N | @SIC3 | @SO2 | @S2 | @HS2 | @H2S2 | E- | BULK | SURFACE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5.000000e-01 | 1.000000e-30 | 0.250000 | 1.000000e-30 | 1.000000e-30 | 0.1 | 1.000000e-30 | 1.000000e-30 | 1.000000e-10 | 1.770000e-04 | ... | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.823239e-04 | 1.000000e-30 | 1.000000e-30 |
| 1 | 5.000000e-01 | 9.674341e-18 | 0.250000 | 9.479999e-18 | 7.975011e-25 | 0.1 | 2.054000e-18 | 1.993850e-26 | 1.000005e-10 | 1.770000e-04 | ... | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.823239e-04 | 5.753474e-24 | 7.485971e-15 |
| 2 | 5.000000e-01 | 9.674345e-17 | 0.250000 | 9.479987e-17 | 7.800679e-23 | 0.1 | 2.054000e-17 | 1.950169e-24 | 1.000051e-10 | 1.770000e-04 | ... | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.823239e-04 | 5.479492e-22 | 7.386762e-14 |
| 3 | 5.000000e-01 | 9.674388e-16 | 0.250000 | 9.479870e-16 | 7.796568e-21 | 0.1 | 2.054000e-16 | 1.949126e-22 | 1.000514e-10 | 1.770000e-04 | ... | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.823239e-04 | 5.461842e-20 | 7.376787e-13 |
| 4 | 5.000000e-01 | 9.674822e-15 | 0.250000 | 9.478701e-15 | 7.795795e-19 | 0.1 | 2.054000e-15 | 1.948788e-20 | 1.005144e-10 | 1.770000e-04 | ... | 1.000001e-30 | 1.000001e-30 | 1.000001e-30 | 1.000001e-30 | 1.000001e-30 | 1.000001e-30 | 1.000001e-30 | 1.823239e-04 | 5.458412e-18 | 7.374509e-12 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 92 | 2.771799e-08 | 1.276230e-08 | 0.040089 | 6.657004e-15 | 1.254442e-10 | 0.1 | 4.005204e-10 | 1.496219e-15 | 8.792585e-14 | 2.268114e-13 | ... | 7.695199e-07 | 1.030074e-08 | 1.125875e-29 | 1.098211e-12 | 1.481852e-08 | 1.379987e-08 | 2.825312e-08 | 1.303557e-08 | 4.601581e-01 | 4.981617e-06 |
| 93 | 2.771874e-08 | 1.276193e-08 | 0.040089 | 6.656996e-15 | 1.254478e-10 | 0.1 | 4.005205e-10 | 1.496215e-15 | 8.866788e-14 | 2.214815e-13 | ... | 7.695199e-07 | 1.030074e-08 | 1.128585e-29 | 1.098211e-12 | 1.481852e-08 | 1.379987e-08 | 2.825312e-08 | 1.303519e-08 | 4.601628e-01 | 4.981617e-06 |
| 94 | 2.771940e-08 | 1.276161e-08 | 0.040089 | 6.656988e-15 | 1.254510e-10 | 0.1 | 4.005206e-10 | 1.496211e-15 | 8.929955e-14 | 2.168243e-13 | ... | 7.695199e-07 | 1.030074e-08 | 1.131024e-29 | 1.098211e-12 | 1.481852e-08 | 1.379987e-08 | 2.825312e-08 | 1.303485e-08 | 4.601672e-01 | 4.981617e-06 |
| 95 | 2.771998e-08 | 1.276133e-08 | 0.040090 | 6.656981e-15 | 1.254537e-10 | 0.1 | 4.005207e-10 | 1.496207e-15 | 8.983886e-14 | 2.127334e-13 | ... | 7.695199e-07 | 1.030074e-08 | 1.133223e-29 | 1.098211e-12 | 1.481852e-08 | 1.379987e-08 | 2.825313e-08 | 1.303456e-08 | 4.601713e-01 | 4.981617e-06 |
| 96 | 2.772049e-08 | 1.276107e-08 | 0.040090 | 6.656975e-15 | 1.254562e-10 | 0.1 | 4.005208e-10 | 1.496204e-15 | 9.030015e-14 | 2.091234e-13 | ... | 7.695199e-07 | 1.030074e-08 | 1.135211e-29 | 1.098211e-12 | 1.481852e-08 | 1.379987e-08 | 2.825313e-08 | 1.303430e-08 | 4.601752e-01 | 4.981617e-06 |
97 rows × 335 columns
With that done, we now have a file containing the final abundances of a cloud of gas after this collapse: param_dict["abundSaveFile"] we can pass this to our hot core model to use those abundances as our initial abundances.
Running the Science Model (Stage 2)
We need to change just a few things in param_dict to set up the hot core model. The key one is that UCLCHEM saves final abundances to abundSaveFile but loads them from abundLoadFile so we need to swap that key over to make the abundances we just produced our initial abundances.
We also want to turn off freefall and change how long the model runs for.
# change other bits of input to set up stage 2
param_dict["initialDens"] = 1e6
param_dict["finalTime"] = 1e6
param_dict["freefall"] = False
# freeze out is completely overwhelmed by thermal desorption
# so turning it off has no effect on abundances but speeds up integrator.
param_dict["freezeFactor"] = 0.0
# param_dict["abstol_factor"]=1e-18
# param_dict["reltol"]=1e-12
df_stage2_physics, df_stage2_chemistry, df_stage2_rates, final_abundances, result = (
uclchem.model.hot_core(
temp_indx=3,
max_temperature=300.0,
param_dict=param_dict,
return_dataframe=True,
starting_chemistry=final_abundances,
)
)
At T(=R1) and step size H(=R2), the error
test failed repeatedly or with ABS(H) = HMIN.
In the above message, R1 = 0.7429814585520D+13 R2 = 0.1131816175613D-03 ISTATE -4 - shortening step
df_stage2 = pd.concat((df_stage2_physics, df_stage2_chemistry), axis=1)
df_stage2
| Time | Density | gasTemp | dustTemp | Av | radfield | zeta | dstep | H | H+ | ... | @OCS | @C4N | @SIC3 | @SO2 | @S2 | @HS2 | @H2S2 | E- | BULK | SURFACE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.000000e+00 | 1000000.0 | 10.000000 | 10.000000 | 193.875 | 1.0 | 1.0 | 1.0 | 2.772049e-08 | 1.276107e-08 | ... | 7.695199e-07 | 1.030074e-08 | 1.135211e-29 | 1.098211e-12 | 1.481852e-08 | 1.379987e-08 | 2.825313e-08 | 1.303430e-08 | 4.601752e-01 | 4.981617e-06 |
| 1 | 1.000000e-07 | 1000000.0 | 10.000000 | 10.000000 | 193.875 | 1.0 | 1.0 | 1.0 | 2.772049e-08 | 1.276107e-08 | ... | 7.695199e-07 | 1.030074e-08 | 1.135211e-29 | 1.098211e-12 | 1.481852e-08 | 1.379987e-08 | 2.825313e-08 | 1.303430e-08 | 4.601752e-01 | 4.981617e-06 |
| 2 | 1.000000e-06 | 1000000.0 | 10.000000 | 10.000000 | 193.875 | 1.0 | 1.0 | 1.0 | 2.772049e-08 | 1.276107e-08 | ... | 7.695199e-07 | 1.030074e-08 | 1.135211e-29 | 1.098211e-12 | 1.481852e-08 | 1.379987e-08 | 2.825313e-08 | 1.303430e-08 | 4.601752e-01 | 4.981617e-06 |
| 3 | 1.000000e-05 | 1000000.0 | 10.000000 | 10.000000 | 193.875 | 1.0 | 1.0 | 1.0 | 2.772049e-08 | 1.276107e-08 | ... | 7.695199e-07 | 1.030074e-08 | 1.135211e-29 | 1.098211e-12 | 1.481852e-08 | 1.379987e-08 | 2.825313e-08 | 1.303430e-08 | 4.601752e-01 | 4.981617e-06 |
| 4 | 1.000000e-04 | 1000000.0 | 10.000003 | 10.000003 | 193.875 | 1.0 | 1.0 | 1.0 | 2.772049e-08 | 1.276107e-08 | ... | 7.695199e-07 | 1.030074e-08 | 1.135211e-29 | 1.098211e-12 | 1.481852e-08 | 1.379987e-08 | 2.825313e-08 | 1.303430e-08 | 4.601752e-01 | 4.981617e-06 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 278 | 9.600100e+05 | 1000000.0 | 300.000000 | 300.000000 | 193.875 | 1.0 | 1.0 | 1.0 | 2.603291e-06 | 1.992348e-13 | ... | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 3.855010e-08 | 8.936003e-29 | 8.936555e-29 |
| 279 | 9.700100e+05 | 1000000.0 | 300.000000 | 300.000000 | 193.875 | 1.0 | 1.0 | 1.0 | 2.606933e-06 | 1.988969e-13 | ... | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 3.839686e-08 | 8.944924e-29 | 8.945484e-29 |
| 280 | 9.800100e+05 | 1000000.0 | 300.000000 | 300.000000 | 193.875 | 1.0 | 1.0 | 1.0 | 2.610524e-06 | 1.985598e-13 | ... | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 3.824463e-08 | 8.953846e-29 | 8.954413e-29 |
| 281 | 9.900100e+05 | 1000000.0 | 300.000000 | 300.000000 | 193.875 | 1.0 | 1.0 | 1.0 | 2.614064e-06 | 1.982235e-13 | ... | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 3.809338e-08 | 8.962768e-29 | 8.963344e-29 |
| 282 | 1.000010e+06 | 1000000.0 | 300.000000 | 300.000000 | 193.875 | 1.0 | 1.0 | 1.0 | 2.617553e-06 | 1.978879e-13 | ... | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 1.000000e-30 | 3.794309e-08 | 8.971691e-29 | 8.972274e-29 |
283 rows × 343 columns
Note that we've changed made two changes to the parameters here which aren't strictly necessary but can be helpful in certain situations.
Since the gas temperature increases throughout a hot core model, freeze out is much slower than thermal desorption for all but the first few time steps. Turning it off doesn't affect the abundances but will speed up the solution.
We also change abstol and reltol here, largely to demonstrate their use. They control the integrator accuracy and whilst making them smaller does slow down successful runs, it can make runs complete that stall completely otherwise or give correct solutions where lower tolerances allow issues like element conservation failure to sneak in. If your code does not complete or element conservation fails, you can change them.
Checking the Result
With a successful run, we can check the output. We first load the file and check the abundance conservation, then we can plot it up.
uclchem.analysis.check_element_conservation(df_stage2)
{'H': '0.000%', 'N': '0.000%', 'C': '0.000%', 'O': '0.000%'}
df_stage2.iloc[0]
Time 0.000000e+00
Density 1.000000e+06
gasTemp 1.000000e+01
dustTemp 1.000000e+01
Av 1.938750e+02
...
@HS2 1.379987e-08
@H2S2 2.825313e-08
E- 1.303430e-08
BULK 4.601752e-01
SURFACE 4.981617e-06
Name: 0, Length: 343, dtype: float64
species = ["CO", "H2O", "CH3OH", "#CO", "#H2O", "#CH3OH", "@H2O", "@CO", "@CH3OH"]
fig, [ax, ax2] = plt.subplots(1, 2, figsize=(16, 9))
ax = uclchem.analysis.plot_species(ax, df_stage2, species)
settings = ax.set(
yscale="log",
xlim=(1e2, 1e6),
ylim=(1e-10, 1e-2),
xlabel="Time / years",
ylabel="Fractional Abundance",
xscale="log",
)
ax2.plot(df_stage2["Time"], df_stage2["Density"], color="black")
ax2.set(xscale="log")
ax3 = ax2.twinx()
ax3.plot(df_stage2["Time"], df_stage2["gasTemp"], color="red")
ax2.set(xlabel="Time / year", ylabel="Density")
ax3.set(ylabel="Temperature", facecolor="red", xlim=(1e2, 1e6))
ax3.tick_params(axis="y", colors="red")
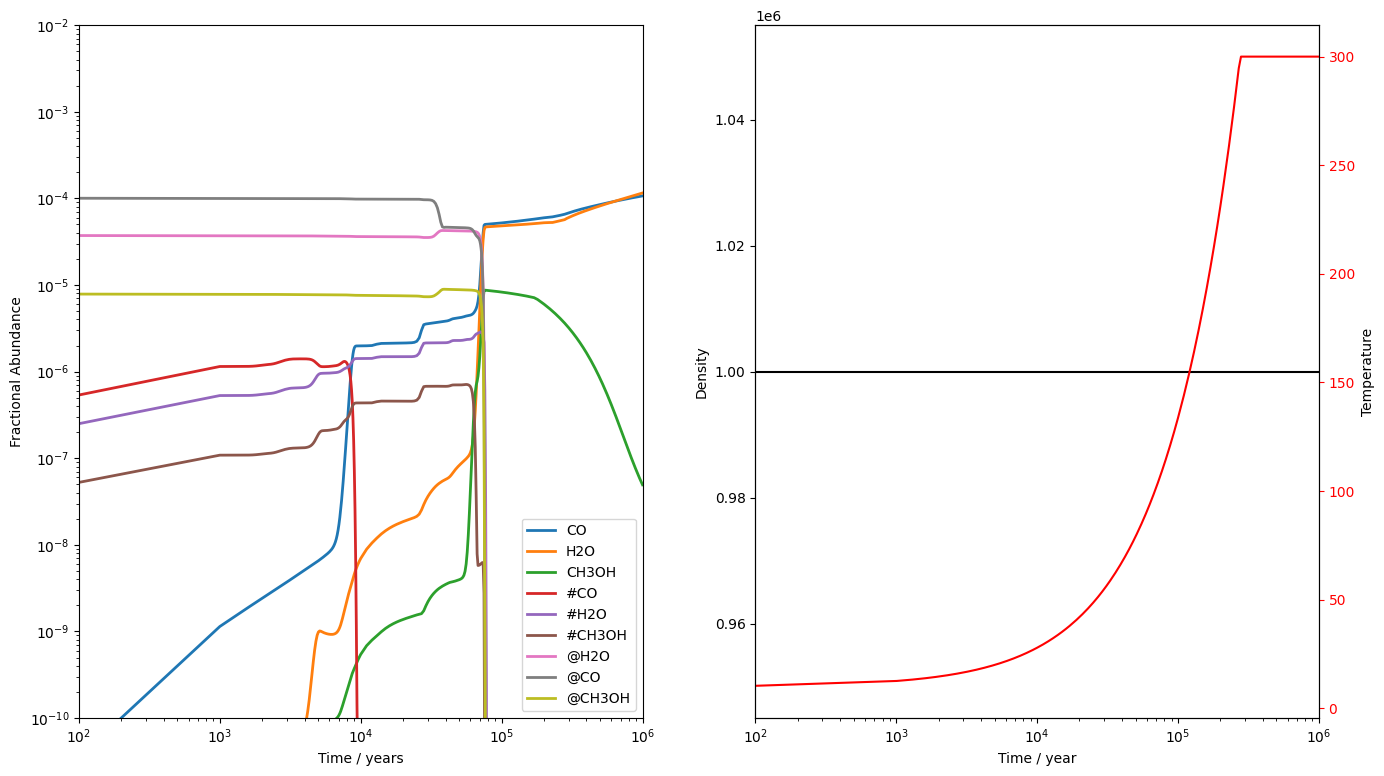
Here, we see the value of running a collapse stage before the science run. Having run a collapse, we start this model with well developed ices and having material in the surface and bulk allows us to properly model the effect of warm up in a hot core. For example, the @CO abundance is and #CO is . As the gas warms to around 30K, the #CO abundance drops drastically as CO's binding energy is such that it is efficiently desorbed from the surface at this temperature. However, the rest of the CO is trapped in the bulk, surrounded by more strongly bound H2O molecules. Thus, the @CO abundance stays high until the gas reaches around 130K, when the H2O molecules are released along with the entire bulk.
Shocks
Essentially the same process should be followed for shocks. Let's run a C-type and J-type shock through a gas of density . Again, we first run a simple cloud model to obtain some reasonable starting abundances, then we can run the shocks.
# set a parameter dictionary for stage 1 collapse model
param_dict = \{
"endAtFinalDensity": False, # stop at finalTime
"freefall": True, # increase density in freefall
"initialDens": 1e2, # starting density
"finalDens": 1e4, # final density
"initialTemp": 10.0, # temperature of gas
"finalTime": 6.0e6, # final time
"rout": 0.1, # radius of cloud in pc
"baseAv": 1.0, # visual extinction at cloud edge.
# "abundSaveFile": "../examples/test-output/shockstart.dat",
\}
df_stage1_physics, df_stage1_chemistry, df_stage1_rates, final_abundances, result = (
uclchem.model.cloud(
param_dict=param_dict,
return_dataframe=True,
)
)
C-shock
We'll first run a c-shock. We'll run a 40 km s shock through a gas of density cm , using the abundances we just produced. Note that c-shock is the only model which returns an additional output in its result list. Not only is the first element the success flag indicating whether UCLCHEM completed, the second element is the dissipation time of the shock. We'll use that time to make our plots look nicer, cutting to a reasonable time. You can also obtain it from uclchem.utils.cshock_dissipation_time().
# change other bits of input to set up phase 2
param_dict["initialDens"] = 1e4
param_dict["finalTime"] = 1e6
if "abundSaveFile" in param_dict:
param_dict.pop("abundSaveFile")
# param_dict["abundLoadFile"]="../examples/test-output/shockstart.dat"
# param_dict["outputFile"]="../examples/test-output/cshock.dat"
(
df_stage2_physics,
df_stage2_chemistry,
df_stage2_rates,
dissipation_time,
final_abundances,
result,
) = uclchem.model.cshock(
shock_vel=40,
param_dict=param_dict,
return_dataframe=True,
starting_chemistry=final_abundances,
)
# result,dissipation_time=result
Cannot have freefall on during cshock setting freefall=0 and continuing
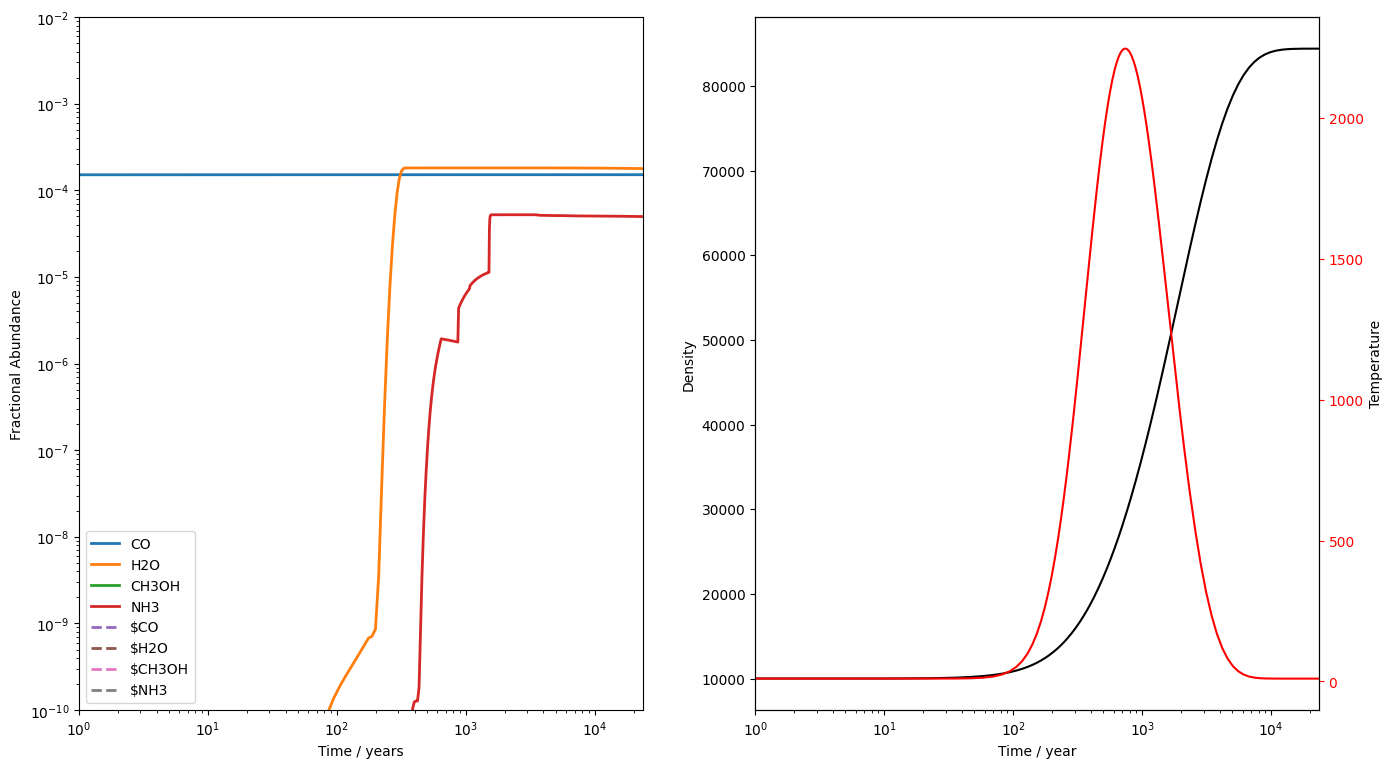
The code completes fine. We do get a couple of warnings though. First, we're informed that freefall must be set to False for the C-shock model. Then we get a few integrator warnings. These are not important and can be ignored as long as the element conservation looks ok. However, it is an indication that the integrator did struggle with these ODEs under these conditions.
df_stage2 = pd.concat((df_stage2_physics, df_stage2_chemistry), axis=1)
uclchem.analysis.check_element_conservation(df_stage2)
{'H': '0.000%', 'N': '0.000%', 'C': '0.000%', 'O': '0.000%'}
# df_stage2.rename(columns=\{"age":"Time", "density":"Density"\}, inplace=True)
species = ["CO", "H2O", "CH3OH", "NH3", "$CO", "$H2O", "$CH3OH", "$NH3"]
fig, [ax, ax2] = plt.subplots(1, 2, figsize=(16, 9))
ax = uclchem.analysis.plot_species(ax, df_stage2, species)
settings = ax.set(
yscale="log",
xlim=(1, 20 * dissipation_time),
ylim=(1e-10, 1e-2),
xlabel="Time / years",
ylabel="Fractional Abundance",
xscale="log",
)
ax2.plot(df_stage2["Time"], df_stage2["Density"], color="black")
ax2.set(xscale="log")
ax3 = ax2.twinx()
ax3.plot(df_stage2["Time"], df_stage2["gasTemp"], color="red")
ax2.set(xlabel="Time / year", ylabel="Density")
ax3.set(ylabel="Temperature", facecolor="red", xlim=(1, 20 * dissipation_time))
ax3.tick_params(axis="y", colors="red")
J-shock
Running a j-shock is a simple case of changing function. We'll run a 10 km s shock through a gas of density cm gas this time. Note that nothing stops us using the intial abundances we produced for the c-shock. UCLCHEM will not check that the initial density matches the density of the abundLoadFile. It may not always be a good idea to do this but we should remember the intial abundances really are just a rough approximation.
By default UCLCHEM uses 500 timepoints for a model, but this turns out not be enough, which is why we increase the number of timepoints to 1500.
# TODO: maybe add a function/method to adjust the number of timepoints in UCLCHEM WITHOUT restarting the kernel
param_dict["initialDens"] = 1e3
param_dict["freefall"] = False # lets remember to turn it off this time
param_dict["reltol"] = 1e-12
shock_vel = 10.0
df_jshock_physics, df_jshock_chemistry, df_jshock_rates, final_abundances, result = (
uclchem.model.jshock(
shock_vel=shock_vel,
param_dict=param_dict,
return_dataframe=True,
starting_chemistry=final_abundances,
timepoints=1500,
)
)
This time, we've turned off the freefall option and made reltol a little more stringent. The j-shock ends up running a bit slower but we get no warnings on this run.
df_jshock = pd.concat((df_jshock_physics, df_jshock_chemistry), axis=1)
# df_jshock.rename(columns=\{"age":"Time", "density":"Density"\}, inplace=True)
uclchem.analysis.check_element_conservation(df_jshock)
{'H': '0.000%', 'N': '0.000%', 'C': '0.000%', 'O': '0.000%'}
df_jshock.shape
(1317, 343)
species = ["CO", "H2O", "CH3OH", "NH3", "$CO", "$H2O", "$CH3OH", "$NH3"]
fig, [ax, ax2] = plt.subplots(1, 2, figsize=(16, 9))
ax = uclchem.analysis.plot_species(ax, df_jshock, species)
settings = ax.set(
yscale="log",
xlim=(1e-7, 1e6),
ylim=(1e-10, 1e-2),
xlabel="Time / years",
ylabel="Fractional Abundance",
xscale="log",
)
ax2.plot(df_jshock["Time"], df_jshock["Density"], color="black")
ax2.set(xscale="log", yscale="log")
ax3 = ax2.twinx()
ax3.plot(df_jshock["Time"], df_jshock["gasTemp"], color="red")
ax2.set(xlabel="Time / year", ylabel="Density")
ax3.set(ylabel="Temperature", facecolor="red", xlim=(1e-7, 1e6))
ax3.tick_params(axis="y", colors="red")
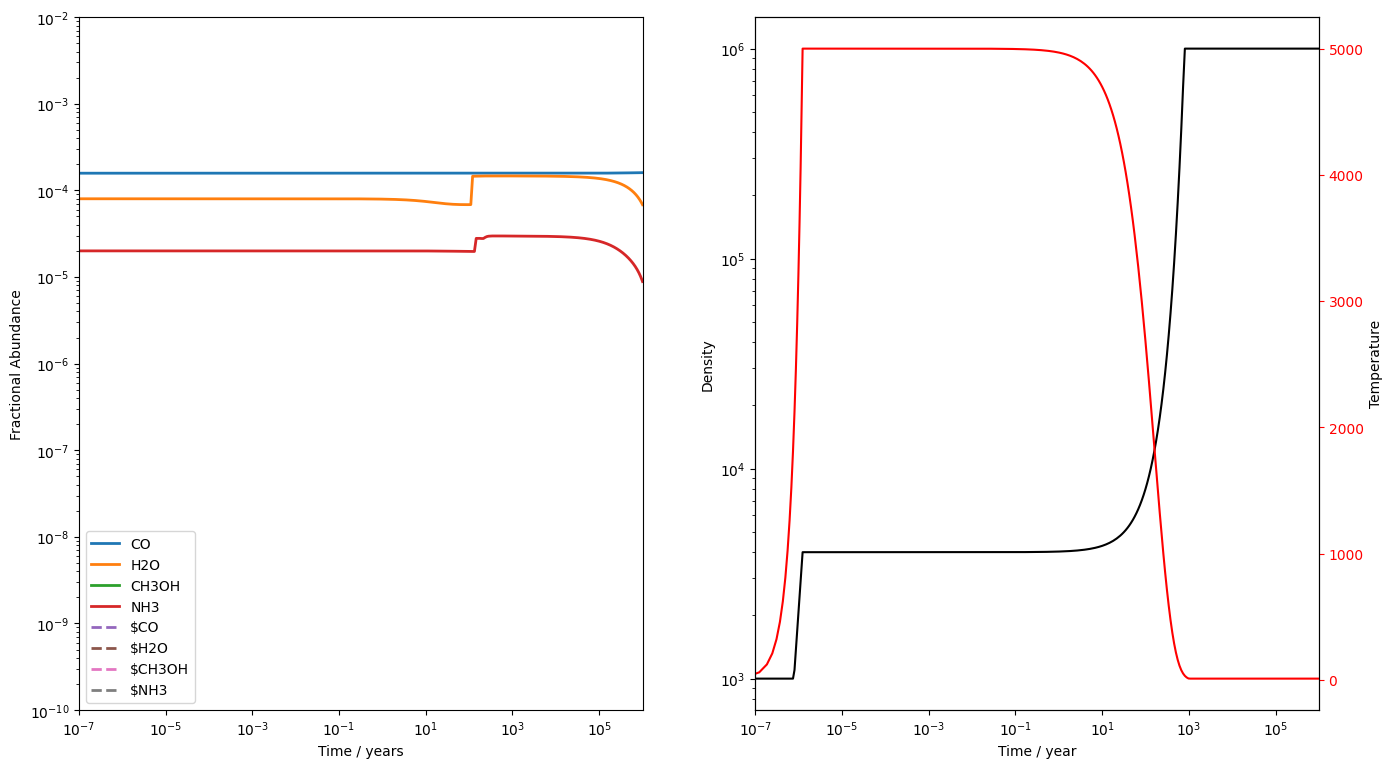
That's everything! We've run various science models using reasonable starting abundances that we produced by running a simple UCLCHEM model beforehand. One benefit of this method is that the abundances are consistent with the network. If we start with arbitrary, perhaps observationally motivated, abundances, it would be possible to initiate the model in a state our network could never produce.
However, one should be aware of the limitations of this method. A freefall collapse from low density to high is not really how a molecular cloud forms and so the abundances are only approximately similar to values they'd truly have in a real cloud. Testing whether your results are sensitive to things like the time you run the preliminary for or the exact density is a good way to make sure these approximations are not problematic.
Bear in mind that you can use abundSaveFile and abundLoadFile in the same model run. This lets you chain model runs together. For example, you could run a c-shock from a cloud model as we did here and then a j-shock with the c-shock's abundances as the initial abundances.